
Frequently Asked Questions
▶ Table of Contents
- How to get started quickly?
- LSU HPC System FAQ
- LONI System FAQ
- LSU HPC Accounts FAQ
- LSU HPC Allocations FAQ
- LONI Accounts FAQ
- LONI Allocations FAQ
- How to unsubscribe from LONI and/or LSU HPC mailing lists?
- How to login to the clusters?
- How to setup your environment with Environment Modules?
- How to share directories for collaborative work?
- How to transfer files?
- How to install utilities and libraries?
- How to background and distribute unrelated processes?
- How to run hybrid MPI and OpenMP jobs?
- How to achieve ppn=N?
- How to monitor PBS stdout and stderr?
- How to decipher underutilization error emails?
- How to establish a remote X11 session?
- How to run interactive jobs?
- How to setup SSH keys?
- How to compile an MPI Program?
- How to install VASP?
- Are LONI or LSU HPC systems backed up?
- Cluster email?
- What is my disk quota on clusters?
- File storage on LONI clusters
- Disk/Storage issues?
- Which text editors are installed on the clusters?
- PBS job chains and dependencies?
- Random number seeds?
- Known issues?
- DOS/Linux/MAC text file problems?
- How to use Singularity container on the clusters?
1. How to get started quickly
Getting started on HPC systems requires several steps that may vary depending on how experienced you are with HPC systems. The items listed here are not meant to be exhaustive - treat as robust starting points.
Everyone
Every HPC system user requires a user account. Some systems also require an allocation account to charge production runs against.
- Visit the applications index to see what software is currently installed. Listings by name and by field (i.e. Computational Biology) are provided. Assistance with installing other software is available.
- Request a LONI and/or LSU user account. Individuals on the LSU campus have access to both sets of resources.
- Be aware that assistance in many forms is always available.
Production efforts on LONI and LSU resources require an allocation of system time in units of core-hours (i.e. SU) against which work is charged. This is a no-cost service, but a proposal of one form or another is required. The holder of an allocation then adds users who may charge against it. Note that only faculty and research staff may request allocations (see allocation policy pages for details).
To request or join an allocation, you must have the appropriate system user account and then visit:
- LONI allocation applications (e.g. LONI resources).
- LSU allocation applications (e.g. LSU resources).
Beginner
See the Training link for the various forms of training that are available, such as weekly tutorials (live and recorded past sessions), and workshops.
- Learn how to connect to an HPC system (SSH, PuTTY, WinSCP).
- Learn basic Linux commands.
- Learn how to edit files (vi/vim editor).
- Learn about the user shell environment (bash shell).
- Learn how to submit jobs (PBS or SLURM)
Advanced
- Learn how to manage data files.
- Learn how to control your applications of choice.
- Learn how to write shell scripts (i.e. job scripts).
- Learn how to install custom software.
- Learn to program in one or more languages.
Expert
- Learn how to debug software (ddt, totalview).
- Learn how to use parallel programming techniques.
- Learn how to profile and optimize code (tau).
- Learn how to manage source code (svn or git).
- Learn how to automate the build process (make).
2. LSU HPC System FAQ
What computing resources are available to LSU HPC users?
The following clusters are in production and open to LSU HPC users
- Philip (philip.hpc.lsu.edu)
- SuperMike-II (mike.hpc.lsu.edu)
- SuperMIC (smic.hpc.lsu.edu)
- Deep Bayou (db1.hpc.lsu.edu)
In addition, users from LSU also have access to computing resources provided by LONI.
Where can I find information on using the LSU HPC systems?
See the LSU HPC Cluster User's Guide for information on connecting to and using the LSU HPC clusters.
Who is eligible for a LSU HPC account?
All faculty and research staff at Louisiana State University Baton Rouge Campus, as well as students pursuing sponsored research activities at LSU, are eligible for a LSU HPC account. For prospective LSU HPC Users from outside LSU, you are required to have a faculty or research staff at LSU as your Collaborator to sponsor you a LSU HPC account.
How can one apply for an account?
Individuals interested in applying for a LSU HPC account should visit this page to begin the account request process. A valid, active institutional email address is required.
Who can sponsor a LSU HPC account or request allocations?
The LSU HPC Resource Allocations Committee require that the Principle Investigators using LSU HPC resources be restricted to full-time faculty or research staff members located at LSU (Baton Rouge campus).
HPC@LSU welcomes members of other institutions that are collaborating with LSU researchers to use LSU HPC resources, but they cannot be the Principle Investigator requesting allocations or granting access. For the Principle Investigator role, Adjunct and Visiting professors do not qualify. They must ask a collaborating full-time professor or research staff member located at LSU to sponsor them and any additional researchers.
How do LSU HPC users change their passwords?
If an LSU HPC password needs to be changed or reset, one must submit a request here to initiate the process. Please note that the email address must be the one used to apply for the LSU HPC account. Like the account request process, you will receive an email which includes a link to the reset form where the new password can be entered. After you confirm your new password, it will not be in effect until one of the LSU HPC administrators approves it, which may take up to a few hours(or even longer during nights & weekends). Please do not request another password reset, you will receive an email notifying that your password reset has been approved.
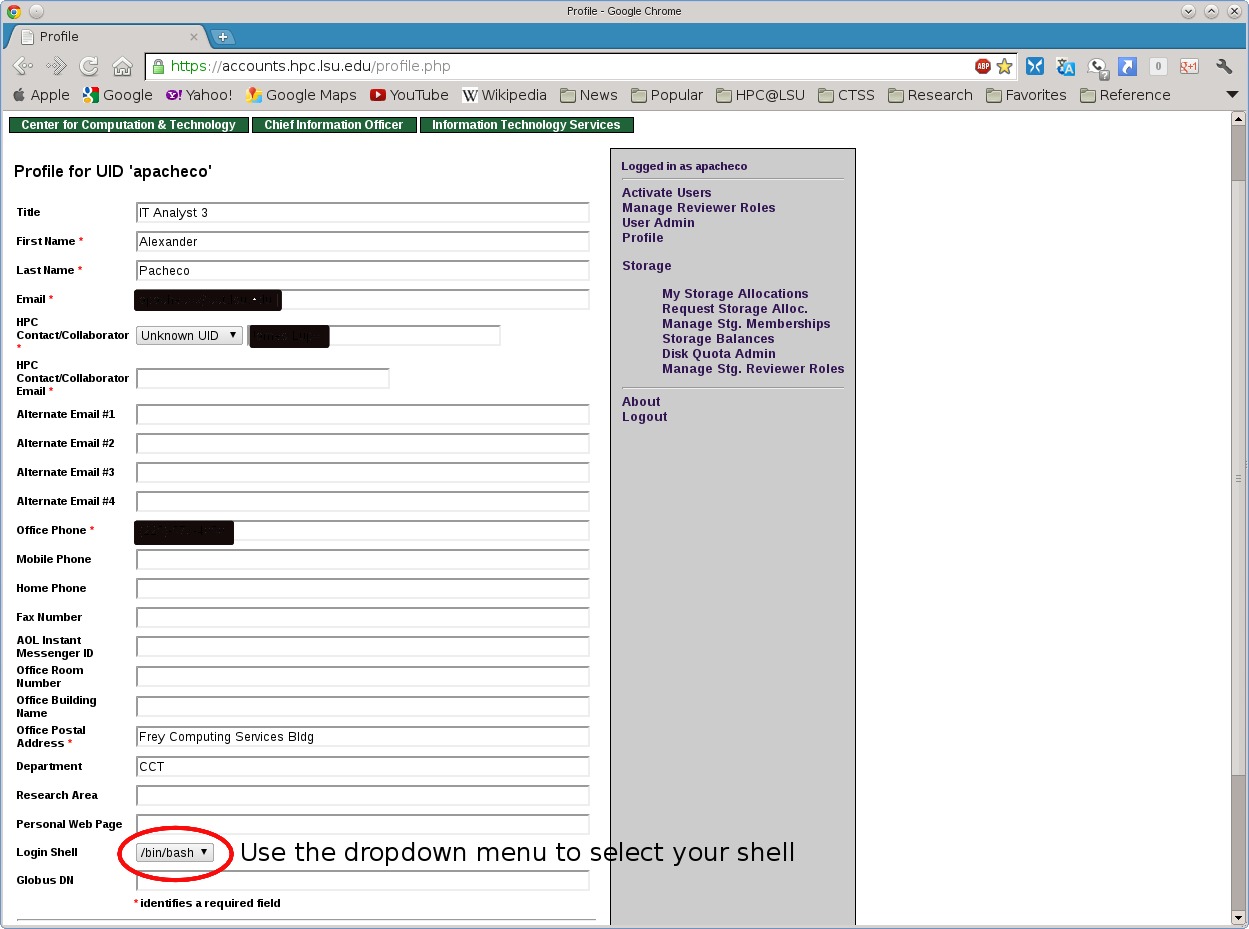
How do LSU HPC users change their login shell?
LSU HPC users can change their login shell on all LSU HPC clusters by visiting their profile on the LSU HPC website
How can users communicate with the LSU HPC systems staff?
Questions for the LSU HPC systems' administrators should be directed to sys-help@loni.org.
Back to top3. LONI System FAQ
What computing resources are available to LONI users?
The following clusters are in production and open to LONI HPC users
Where can I find information on using the LONI systems?
See the LONI User's Guide for information on connecting to and using the LONI clusters.
Who is eligible for a LONI account?
All faculty and research staff at a LONI Member Institution, as well as students pursuing sponsored research activities at these facilities, are eligible for a LONI account. Requests for accounts by research associates not affiliated with a LONI Member Institution will be handled on a case by case basis. For prospective LONI Users from a non-LONI Member Institution, you are required to have a faculty or research staff in one of LONI Member Institutions as your Collaborator to sponsor you a LONI account.
How can one apply for an account?
Individuals interested in applying for a LONI account should visit this page to begin the account request process. A valid, active institutional email address is required.
Who can sponsor a LONI account or request allocations?
LONI provides Louisiana researchers with an advanced optical network and powerful distributed supercomputer resources. The LONI Allocations committee and LONI management require that the Principle Investigators using LONI resources be restricted to full-time faculty or research staff members located at LONI member institutions.
LONI welcomes members of other institutions that are collaborating with Louisiana researchers to use LONI resources, but they cannot be the Principle Investigator requesting allocations or granting access. For the Principle Investigator role, Adjunct and Visiting professors do not qualify. They must ask a collaborating full-time professor or research staff member located at a LONI institution to sponsor them and any additional researchers.
How do LONI users change their passwords?
If a LONI password needs to be changed or reset, one must submit a request here to initiate the process. Please note that the email address must be the one used to apply for the LONI account. Like the account request process, you will receive an email which includes a link to the reset form where the new password can be entered. After you confirm your new password, it will not be in effect until one of the LONI administrators approves it, which may take up to a few hours (or even longer during nights and weekends). Please do not request another password reset, you will receive an email notifying that your password reset has been approved.
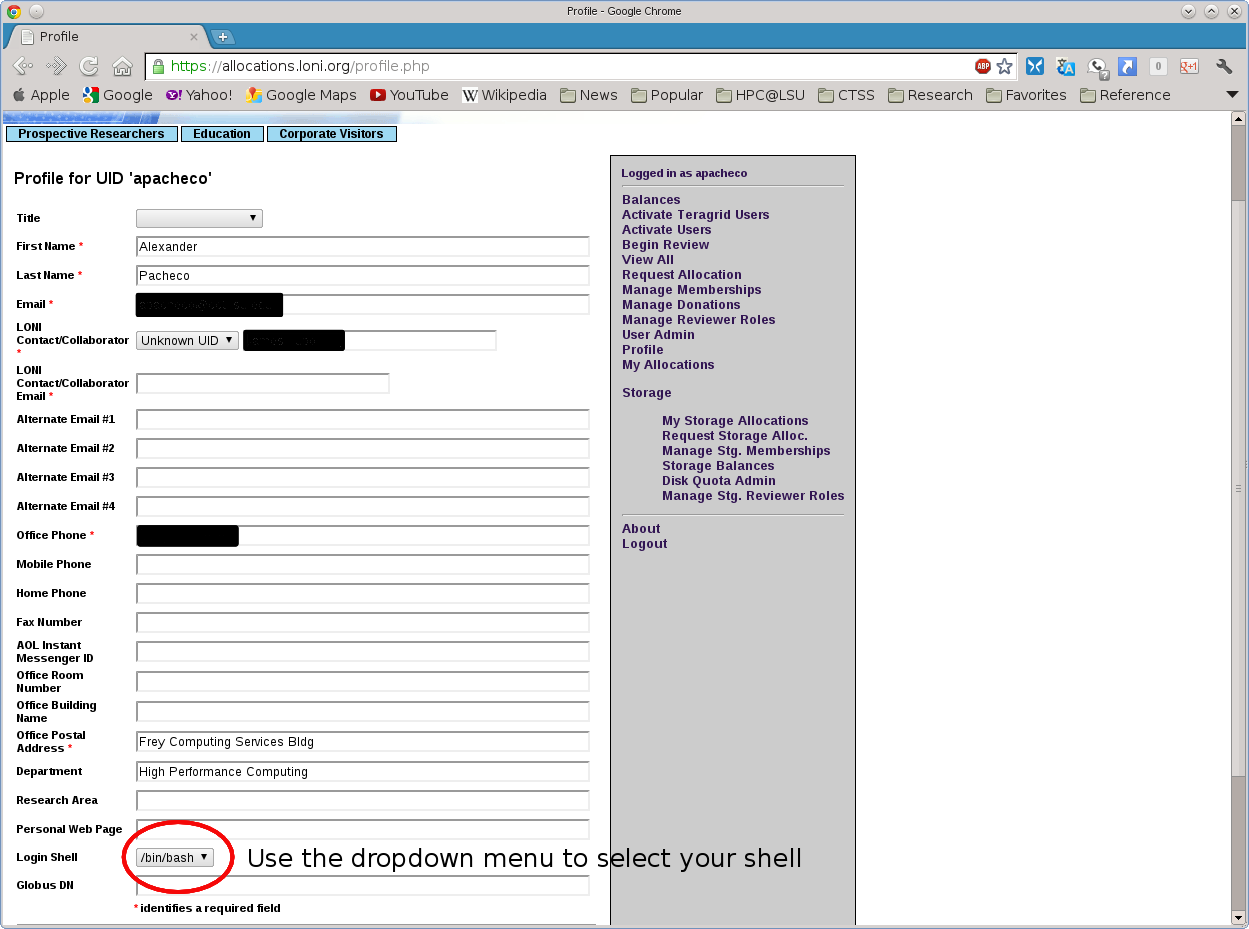
How do LONI users change their login shell?
LONI users can change their login shell on all LONI clusters by visiting their profile on the LONI website
How can users communicate with the LONI systems staff?
Questions for the LONI systems' administrators should be directed to sys-help@loni.org.
Back to top4. LSU HPC Accounts FAQ
Who is eligible for a LSU HPC account?
All faculty and research staff at Louisiana State University Baton Rouge Campus, as well as students pursuing sponsored research activities at LSU, are eligible for a LSU HPC account. For prospective LSU HPC Users from outside LSU, you are required to have a faculty or research staff at LSU as your Collaborator to sponsor you an LSU HPC account.
How can one apply for an account?
Individuals interested in applying for a LSU HPC account should visit this page to begin the account request process. A valid, active institutional email address is required.
Who can sponsor a LSU HPC account or request allocations?
The LSU HPC Resource Allocations Committee require that the Principle Investigators using LSU HPC resources be restricted to full-time faculty or research staff members located at LSU (Baton Rouge campus).
HPC@LSU welcomes members of other institutions that are collaborating with LSU researchers to use LSU HPC resources, but they cannot be the Principle Investigator requesting allocations or granting access. For the Principle Investigator role, Adjunct and Visiting professors do not qualify. They must ask a collaborating full-time professor or research staff member located at LSU to sponsor them and any additional researchers.
Back to top5. LSU HPC Allocations FAQ
How do I access the LSU HPC Allocations website?
To access LSU HPC Allocations, please login to your LSU HPC Profile. Once logged in you should see links on the right sidebar for Balances (to find out current status and usage of your allocations) and Request Allocations (to join or request a new allocations).
How do I find out my active allocations and remaining balances?
Method1
login to your LSU HPC Profile. Once logged in you should see links on the right sidebar for Balances (to find out current status and usage of your allocations).
Method2
Login to any LSU HPC cluster, then run the "balance" command.
[lyan1@mike1 ~]$ balance ======================= Allocation information for lyan1 ======================= Proj. Name| Alloc| Balance| Deposited| %Used| Days Left| End -------------------------------------------------------------------------------- hpc_hpcadmin3|hpc_hpcadmin3 on @mike2| 96718.18| 100000.00| 3.28| 353|2017-06-30 hpc_train_2017|hpc_train_2017 on @mike2| 24968.34| 25000.00| 0.13| 263|2017-04-01 Note: Balance and Deposit are measured in CPU-hours
Method3
Login to any LSU HPC cluster, then run the "showquota" command.
[lyan1@mike1 ~]$ showquota
Hard disk quotas for user lyan1 (uid 24106):
Filesystem MB used quota files fquota
/homem 4305 5000 70073 0
/work 276 0 70719 4000000
/project 99951 100000 359579 4000000
CPU Allocation SUs remaining:
hpc_hpcadmin3: 96730.05
hpc_train_2017: 24968.34
How do I request a new allocation?
Note: Only faculty members, permanent research staff members and postdoctoral researchers (subject to LSU HPC Resource Allocations Committee Chair review and approval) at the LSU Baton Rouge campus are eligible to be the PI of an allocation. If you are not eligible, please let an eligible PI submit a request and you can join it after it is approved.
Postdoctoral researchers are also eligible to be the PI for both small and research computational allocations (they are NOT eligible for sponsoring user accounts). All research allocation requests submitted by postdoctoral researchers must include 1) "Postdoctoral advisor: [fill in the name of advisor]" in the header (below the proposal title); and 2) a letter from the postdoctoral advisor stating that he or she fully supports the request. Support letters should be appended to the proposal.
To request a new allocation, you first need to login to your LSU HPC Profile and then click on the "Request Allocation" link in the right sidebar. You will see two links there: "New Allocation" and "Join Allocation". Click on the first link. You will then be presented with the Allocation Request form that you need to fill out. Click the "Submit Request" button after you have completed filling the form. The LSU HPC Resource Allocation Committee (HPCRAC) member will review your allocation and let you know of their decision via email. HPC@LSU Support staff do not make decisions on allocations. In case your allocation request has not been responded to in a timely manner, you can either email the HPCRAC committee member directly or email the help desk who will forward the email to appropriate committee member(s).
Would it be possible to request a rollover or extension of an allocation?
In order to keep the accounting straight, allocations cannot be rolled over nor extended. Please apply for a new allocation.
How do I request a new allocation based on my current allocation?
If you have owned allocation before, you can login to your LSU HPC Profile, click on "My Allocations" in the right side bar, and click on "clone/edit" next to your current allocation. The form will be automatically populated using the data of the current one. The form can be edited as necessary, or left everything unchanged.
How do I join an allocation of another PI?
To join an existing allocation of another PI (either your professor, collaborator or our training allocation), you first need to login to your LSU HPC Profile and then click on the "Request Allocation" link in the right sidebar. You will see two links there: "New Allocation" and "Join Allocation".
Click on the second link and enter the name, HPC username or email address of PI whose allocation you wish to join (see screenshot below).
If your search is successfull, you will be provided with information of the PI whom you have searched for. Click the "Join Projects" button
You will then be presented with a list of allocations for the PI. Click on the "Join" button for the allocation which you wish to join.
The PI will recieve an email requesting him/her to confirm adding you to their allocation. HPC@LSU staff do not add users to an existing allocation of a PI, please do not email the support staff to add you to an allocation. You need to this yourself. If you are planning on attending the HPC Training, please read the instructions that are sent in the training confirmation email.
How does a PI apply for Early Allocation Access?
What is Early Allocation Access?
LSU HPC allows early allocation access, through which a PI could request as much as 25% of a new research allocation request to be activated immediately. The relevant sections of policy statements can be found here:
LSU HPC policy - 3.5 Early Allocation Process
Procedure:
-
Then the PI should send an email to sys-help@loni.org, requesting early allocation access using the following template:
Email Title: Early Allocation Access Request: your_allocation_request_name (The allocation request should already be submitted through HPC allocation request page) A justification paragraph describing your reason for Early Allocation Access Request, including your past allocation usage history, if you have never used HPC resources please include your allocation usage history in other institutions/sites.
- The committee will make a decision based on the justification request. If it's approved, we will activate 25% of the allocation request.
Where can I get more information?
Please look through the LSU HPC Policy page for more information on allocation types and HPCRAC contact information. Back to top
6. LONI Accounts FAQ
Who is eligible for a LONI account?
All faculty and research staff at a LONI Member Institution, as well as students pursuing sponsored research activities at these facilities, are eligible for a LONI account. Requests for accounts by research associates not affiliated with a LONI Member Institution will be handled on a case by case basis. For prospective LONI Users from a non-LONI Member Institution, you are required to have a faculty or research staff in one of LONI Member Institutions as your Collaborator to sponsor you a LONI account.
How can one apply for an account?
Individuals interested in applying for a LONI account should visit this page to begin the account request process. A valid, active institutional email address is required.
Who can sponsor a LONI account or request allocations?
LONI provides Louisiana researchers with an advanced optical network and powerful distributed supercomputer resources. The LONI Allocations committee and LONI management require that the Principle Investigators using LONI resources be restricted to full-time faculty or research staff members located at LONI member institutions.
LONI welcomes members of other institutions that are collaborating with Louisiana researchers to use LONI resources, but they cannot be the Principle Investigator requesting allocations or granting access. For the Principle Investigator role, Adjunct and Visiting professors do not qualify. They must ask a collaborating full-time professor or research staff member located at a LONI institution to sponsor them and any additional researchers.
How long can I keep my LONI account?
LONI accounts are valid as long as you maintain eligibility for a LONI account. However, the Allocation Management clause from the LONI Allocation policy, which is stated below, takes precedence for maintaining an active LONI account.
User accounts must be associated with a valid allocation, and if not, will be retained for a maximum of 1 year pending authorization against a valid allocation.
Back to top7. LONI Allocations FAQ
How do I access the LONI Allocations website?
To access LONI Allocations, please login to your LONI Profile. Once logged in you should see links on the right sidebar for Balances (to find out current status and usage of your allocations) and Request Allocations (to join or request a new allocations).
How do I find out my active allocations and remaining balances?
Method1
Login to your LONI Profile. Once logged in you should see links on the right sidebar for Balances (to find out current status and usage of your allocations).
Method2
Login to any LONI cluster, then run the "balance" command.
[ychen64@qb2 ~]$ balance ====================== Allocation information for ychen64 ====================== Proj. Name| Alloc| Balance| Deposited| %Used| Days Left| End -------------------------------------------------------------------------------- loni_train_2018|loni_train_2018 on @Dell_Cluster| 43048.06| 50000.00| 13.90| 285|2019-04-01 Note: Balance and Deposit are measured in CPU-hours
Method3
Login to any LONI cluster, then run the "showquota" command.
[ychen64@qb2 ~]$ showquota
Hard disk quotas for user ychen64 (uid 11596):
Filesystem MB used quota files fquota
/home 4418 5000 15453 0
/work 16900 0 344472 4000000
CPU Allocation SUs remaining:
loni_loniadmin1: 452559.52
loni_train_2018: 43048.06
How do I request a new allocation
Note: Only faculty members, permanent research staff members at the LONI institution are eligible to be the PI of an allocation. If you are not eligible, please let an eligible PI submit a request and you can join it after it is approved.
To request a new allocation, you first need to login to your LONI Profile and then click on the "Request Allocation" link in the right sidebar. You will see two links there: "New Allocation" and "Join Allocation". Click on the first link. You will then be presented with the Allocation Request form that you need to fill out. Click the "Submit Request" button after you have completed filling the form. The LONI Resource Allocation Committee (LRAC) member will review your allocation and let you know of their decision via email. HPC@LSU Support staff do not make decisions on allocations. In case your allocation request has not been responded to in a timely manner, you can either email the LRAC committee member directly or email the help desk who will forward the email to appropriate committee member(s).
Would it be possible to request a rollover or extension of an allocation?
In order to keep the accounting straight, allocations cannot be rolled over nor extended. Please apply for a new allocation.
How do I request a new allocation based on my current allocation?
If you have owned allocation before, you can login to your LONI Profile, click on "My Allocations" in the right side bar, and click on "clone/edit" next to your current allocation. The form will be automatically populated using the data of the current one. The form can be edited as necessary, or left everything unchanged.
How do I join an allocation of another PI?
To join an existing allocation of another PI (either your professor, collaborator or our training allocation), you first need to login to your LONI Profile and then click on the "Request Allocation" link in the right sidebar. You will see two links there: "New Allocation" and "Join Allocation".
Click on the second link and enter the name, LONI username or email address of PI whose allocation you wish to join.
If your search is successfull, you will be provided with information of the PI whom you have searched for. Click the "Join Projects" button
You will then be presented with a list of allocations for the PI. Click on the "Join" button for the allocation which you wish to join.
The PI will recieve an email requesting him/her to confirm adding you to their allocation. HPC@LSU staff do not add users to an existing allocation of a PI, please do not email the support staff to add you to an allocation. You need to this yourself. If you are planning on attending the HPC Training, please read the instructions that are send in the training confirmation email.
How does a PI apply for Early Allocation Access?
What is Early Allocation Access?
LONI HPC allows early allocation access, through which a PI could request as much as 25% of a new research allocation request to be activated immediately. The relevant sections of policy statements can be found here:
LONI HPC policy - 2.3 Early Allocation Access
Procedure:
- The PI should submit a research allocation request as usual, along with the proposal in pdf format;
-
Then the PI should send an email to sys-help@loni.org, requesting early allocation access using the following template:
Email Title: Early Allocation Access Request: your_allocation_request_name (The allocation request should already be submitted through LONI allocation request page) A justification paragraph describing your reason for Early Allocation Access Request, including your past allocation usage history, if you have never used HPC resources please include your allocation usage history in other institutions/sites.
- The committee will make a decision based on the justification request. If it's approved, we will activate 25% of the allocation request.
Where can I get more information?
Please look through the LONI Policy page for more information on allocation types and LRAC contact information. Back to top
8. How to unsubscribe from LONI and/or LSU HPC mailing lists?
All high performance computing account holders are required by the usage policy to be subscribed to the corresponding LONI/LSU user mailing list. The mailing lists provides the primary communication medium for HPC@LSU system admins to disseminate important information regarding system status, upcoming downtime, training, workshops, etc. The list is maintained by an automated scan of active user accounts.
To deactive your account and subsequently be removed from the list, please submit a request to sys-help@loni.org for account deactivation. Please clearly state that you understand your account will be disabled while being removed from the mailing list..
Back to top9. How to Login to the clusters?
Utilities
Interactive Utilities
Only ssh access is allowed for interactive access. One would issue a command similar to the following:
LSU HPC: ssh -X -Y username@mike.hpc.lsu.edu LONI: ssh -X -Y username@qbc.loni.org
The user would then be prompted for password. The -X -Y flags allow for X11 forwarding to be set up automagically.
For a Windows client, please look at the MobaXterm utility.
Accessibility
On Campus
All host instition networks should be able to directly connect to any LONI machine since a connection to the Internet 2 network is available.
At Home
It is possible that direct connection to a LONI machine from home fails. To access LONI machines from home, a user should use one of the following methods:
- Preferred Method: Login to a machine on Internet2 network, all machines at your host institution are on Internet2 network.
- Not Tested: Connect using your host institution's VPN.
- LSU Faculty, Staff and Students can download VPN Client software from Tigerware
- Others, please contact your IT department for VPN Client software.
10. How to setup your environment with Environment Modules?
The information here is applicable to LSU HPC and LONI systems.
h4
Shells
A user may choose between using /bin/bash and /bin/tcsh. Details about each shell follows.
/bin/bash
System resource file: /etc/profile
When one access the shell, the following user files are read in if they exist (in order):
- ~/.bash_profile (anything sent to STDOUT or STDERR will cause things like rsync to break)
- ~/.bashrc (interactive login only)
- ~/.profile
When a user logs out of an interactive session, the file ~/.bash_logout is executed if it exists.
The default value of the environmental variable, PATH, is set automatically using Modules. See below for more information.
/bin/tcsh
The file ~/.cshrc is used to customize the user's environment if his login shell is /bin/tcsh.
Modules
Modules is a utility which helps users manage the complex business of setting up their shell environment in the face of potentially conflicting application versions and libraries.
Default Setup
When a user logs in, the system looks for a file named .modules in their home directory. This file contains module commands to set up the initial shell environment.
Viewing Available Modules
The command
$ module avail
displays a list of all the modules available. The list will look something like:
--- some stuff deleted --- velvet/1.2.10/INTEL-14.0.2 vmatch/2.2.2 ---------------- /usr/local/packages/Modules/modulefiles/admin ----------------- EasyBuild/1.11.1 GCC/4.9.0 INTEL-140-MPICH/3.1.1 EasyBuild/1.13.0 INTEL/14.0.2 INTEL-140-MVAPICH2/2.0 --- some stuff deleted ---
The module names take the form appname/version/compiler, providing the application name, the version, and information about how it was compiled (if needed).
Managing Modules
Besides avail, there are other basic module commands to use for manipulating the environment. These include:
add/load mod1 mod2 ... modn . . . Add modules rm/unload mod1 mod2 ... modn . . Remove modules switch/swap mod . . . . . . . . . Switch or swap one module for another display/show . . . . . . . . . . List modules loaded in the environment avail . . . . . . . . . . . . . . List available module names whatis mod1 mod2 ... modn . . . . Describe listed modules
The -h option to module will list all available commands.
Back to top11. How to share directories for collaborative work?
Introduction
Often, users collaborating on a project wish to share their files with others in a common set of directories. Unfortunately, many decide to use a single login username as a group user. For security reasons, the sharing of accounts is explicitly forbidden by LONI and HPC@LSU policy, and such practices may result in the suspension of access for all involved.
There are two approaches to sharing files. The first method does restrict access to read-only, but may be setup by anyone. The caveat is any user on the system will be able to read the files, not just the intended collaborators. To achieve this, simply make sure that all directories in the path have read/execute permission for the group, and that the files had read permission for the group.
Set group read/execute permission with a command like:
$ chmod 750 dirname or $ chmod g+rx dirname
Likewise, group read permission on a file can be set with:
$ chmod 640 filename or $ chmod g+r filename
Note that the numerical method is preferred.
The second method allows a group of collaborators to have full access to files: read, write, and/or, execute. This requires that a PI-qualified individual applies for a /project storage allocation. As part of the application, request that a user group be created to allow shared access and provide a list of user names to be included in the group. Members of the group can then place files in the /project directory, and change group ownership to the storage group. Other members of the group will then be able to access the files, include changing permissions.
Not every machine has /project space, but those that do allow allocations to be applied for via the appropriate allocation request pages:
For advice or additional information, contact sys-help@loni.org
More Information
- Using umask to set default permissions of files and directories created by users
- Traditional Unix File System Permissions
12. How to transfer files?
Selecting the Right Method
- SCP: transfer single and unique files
- rsync: transfer hierarchical data, such a directory and its member files, It is able to detect what has changed between the source and destination data, and saves time by only transmitting these changes
- BBCP: transfer large data file by providing higher speed via multiple steams.
What is NOT Available
- FTP (file transfer protocol, and not to be confused with SFTP)
- rcp (remote copy)
Click here for detailed file transfer information
Back to top13. How to install utilities and libraries?
Typically, a user has the permissions to compile and "install" their own libraries and applications. Obviously, a non-root user cannot write to the protected systems library directories, but there is enough space in their home directory, work or project directory to store such tools and libraries.
For additional installation information please see the installation details page.
Back to top14. How to background and distribute unrelated processes?
Introduction
All compute nodes have more than one core/processor, so even if the job is not explicitly parallel (using OpenMP or MPI), it is still beneficial to be able to launch multiple jobs in a single submit script. This document will briefly explain how to launch multiple processes on a single computer node and among 2 or more compute nodes.
Note this method does NOT facilitate communication among processes, and is therefore not appropriate for use with parallelized executables using MPI; it is still okay to invoke multithreaded executables because they are invoked initially as a single process. The caveat there is one should not use more threads than there are cores on a single computer node.
Basic Use Case
A user has a serial executable that they wish to run multiple times on LONI/LSU HPC resources, but wishes to run many per submission script. Instead of submitting one queue script per serial execution, and wishing not to have any idle processors on one or more of the many-core compute nodes available, the user wishes to launch a serial process per available core.
Required Tools
- the shell (bash)
- ssh (for distributing processes to remote compute nodes)
Launching Multiple Processes - Basic Example
On a single computer node
This example assumes one knows of the number of available processors on a a single node. The following example is a bash shell script that launches each process and backgrounds the command using the & symbol.
#!/bin/bash # -- the following 8 lines issue a command, using a subshell, # into the background this creates 8 child processes, belonging # to the current shell script when executed /path/to/exe1 & # executable/script arguments may be passed as expected /path/to/exe2 & /path/to/exe3 & /path/to/exe4 & /path/to/exe5 & /path/to/exe6 & /path/to/exe7 & /path/to/exe8 & # -- now WAIT for all 8 child processes to finish # this will make sure that the parent process does not # terminate, which is especially important in batch mode wait
On multiple compute nodes
Distributing processes onto remote compute nodes builds upon the single node example. In the case of wanting to use multiple compute nodes, one can use the 8 commands from above for the mother superior node (i.e., the "home" node, which will be the compute node that the batch schedular uses to execute the shell commands contained inside of the queue script). For the remote nodes, one must use the ssh to launch the command on the remote host.
#!/bin/bash # Define where the input files are export WORKDIR=/path/to/where/i/want/to/run/my/job # -- the following 8 lines issue a command, using a subshell, # into the background this creates 8 child processes, belonging # to the current shell script when executed # -- for mother superior, or "home", compute node /path/to/exe1 & /path/to/exe2 & /path/to/exe3 & /path/to/exe4 & /path/to/exe5 & /path/to/exe6 & /path/to/exe7 & /path/to/exe8 & # -- for an additional, remote compute node # Assuming executable is to be run on WORKDIR ssh -n remotehost 'cd '$WORKDIR'; /path/to/exe1 ' & ssh -n remotehost 'cd '$WORKDIR'; /path/to/exe2 ' & ssh -n remotehost 'cd '$WORKDIR'; /path/to/exe3 ' & ssh -n remotehost 'cd '$WORKDIR'; /path/to/exe4 ' & ssh -n remotehost 'cd '$WORKDIR'; /path/to/exe5 ' & ssh -n remotehost 'cd '$WORKDIR'; /path/to/exe6 ' & ssh -n remotehost 'cd '$WORKDIR'; /path/to/exe7 ' & ssh -n remotehost 'cd '$WORKDIR'; /path/to/exe8 ' & # -- now WAIT for all 8 child processes to finish # this will make sure that the parent process does not # terminate, which is especially important in batch mode wait
The example above will spawn 16 commands, 8 of the which run on the local compute node (i.e., mother superior) and 8 run on remotehost. The background token (&) backgrounds the command on the local node (for all 16 commands); the commands sent to remotehost are not backgrounded remotely because this would not allow the local machine to know when the local command (i.e., ssh) completed.
Note as it is often the case that one does not know the identity of the mother superior node or the set of remote compute nodes (i.e., remotehost) when submitting such a script to the batch scheduler, some more programming must be done to determine the identity of these nodes at runtime. The following section considers this and concludes with a basic, adaptive example.
Advanced Example for PBS Queuing Systems
The steps involved in the following example are:
- determine identity of mother superior
- determine list of all remote compute nodes
Assumptions:
- shared file system
- a list of all compute nodes assigned by PBS are contained in a file referenced with the environmental variable, ${PBS_NODEFILE}
- each compute node has 8 processing cores
Note this example still requires that one knows the number of cores available per compute node; in this example, 8 is assumed.
!#/bin/bash
# Define where the input files are
export WORKDIR=/path/to/where/i/want/to/run/my/job
# -- Get List of Unique Nodes and put into an array ---
NODES=($(uniq $PBS_NODEFILE ))
# -- Assuming all input files are in the WORKDIR directory (change accordingly)
cd $WORKDIR
# -- The first array element contains the mother superior
# while the second onwards contains the worker or remote nodes --
# -- for mother superior, or "home", compute node
/path/to/exe1 &
/path/to/exe2 &
/path/to/exe3 &
/path/to/exe4 &
/path/to/exe5 &
/path/to/exe6 &
/path/to/exe7 &
/path/to/exe8 &
# -- Launch 8 processes on the first remote node --
ssh ${NODES[1]} ' \
cd '$WORKDIR' \
/path/to/exe1 & \
/path/to/exe2 & \
/path/to/exe3 & \
/path/to/exe4 & \
/path/to/exe5 & \
/path/to/exe6 & \
/path/to/exe7 & \
/path/to/exe8 & ' &
# Repeat above script for other remote nodes
# Remember that bash arrays start from 0 not 1 similar to C Language
# You can also use a loop over the remote nodes
#NUMNODES=$(uniq $PBS_NODEFILE | wc -l | awk '{print $1-1}')
# for i in $(seq 1 $NUMNODES ); do
# ssh -n ${NODES[$i]} ' launch 8 processors ' &
# done
# -- now WAIT for all child processes to finish
# this will make sure that the parent process does not
# terminate, which is especially important in batch mode
wait
Submitting to PBS
Now let's assume you have 128 tasks to run. You can do this by running on 16 8-core nodes using PBS. If one task takes 7 hours, and allowing a 30 minute safety margin, the following qsub command line will take care of running all 128 tasks:
% qsub -I -A allocation_account -V -l walltime=07:30:00,nodes=16:ppn=8
When the script executes, it will find 16 node names in its PBS_NODEFILE, run 1 set of 8 tasks on the mother superior, and 15 sets of 8 on the remote nodes.
More information on submitting to the PBS queue can be accessed at the frequently asked questions page.
Advanced Usage Possibilities
1. executables in the above script can take normal argments and flags; e.g.:
/path/to/exe1 arg1 arg2 -flag arg3 &
2. one can, technically, initiate multithreaded executables; the catch is to make sure there is only one thread per processing core is allowed; the following example launches 4, 2-threaded executables (presumably using OpenMP) locally - thus consuming all 8 (i.e., 4 processes * 2 threads/process), each.
# "_r" simply denotes that executable is multithreaded OMP_NUM_THREADS=2 /path/to/exe1_r & OMP_NUM_THREADS=2 /path/to/exe2_r & OMP_NUM_THREADS=2 /path/to/exe3_r & OMP_NUM_THREADS=2 /path/to/exe4_r & # -- in total, 8 threads are being executed on the 8 (assumed) cores # contained by this compute node; i.e., there are 4 processes, each # with 2 threads running.
A creative user can get even more complicated, but in general there is no need.
Conclusion
In situations where one wants to take advantage of all processors available on a single compute node or a set of compute nodes to run a number of unrelated processes, using backgrounded processes locally (and via ssh) remotely allows one to do this.
Converting the above scripts to csh and tcsh is straightforward
Using the examples above, one may create a customized solution using the proper techniques. For questions and comments regarding this topic and the examples above, please email sys-help@loni.org.
Back to top15. How to run hybrid MPI and OpenMP jobs?
Combination of MPI and OpenMP in programming can provide high parallel efficiency. For most hybrid codes, OpenMP threads are spread within one MPI task. This kind of hybrid codes are widely used in many fields of science and technology. A sample bash shell script for running hybrid jobs on LSU HPC clusters is provided in the following.
#!/bin/bash #PBS -A my_allocation_code #PBS -q workq #PBS -l walltime=00:10:00 #PBS -l nodes=2:ppn=16 # ppn=16 for SuperMike and ppn=20 for SuperMIC #PBS -V # make sure environments are the same for asigned nodes #PBS -N my_job_name # will be shown in the queue system #PBS -o my_name.out # normal output #PBS -e my_name.err # error output export TASK_PER_NODE=2 # number of MPI tasks per node export THREADS_PER_TASK=8 # number of OpenMP threads per MPI task cd $PBS_O_WORKDIR # go to the path where you run qsub # Get the node names from the PBS node file and gather them to a new file cat $PBS_NODEFILE|uniq>nodefile # Run the hybrid job. # Use "-x OMP_NUM_THREADS=..." to make sure that # the number of OpenMP threads is passed to each MPI task mpirun -npernode $TASK_PER_NODE -x OMP_NUM_THREADS=$THREADS_PER_TASK -machinefile nodefile ./my_exe
Non-uniform memory access (NUMA) is a common issue when running hybrid jobs. The reason causing this issue is that there are two sockets on one CPU card. In theory the parallel efficiency is the highest if the number of OpenMP threads equals the number of cores of each socket in one CPU, that is 8 for SuperMike and 10 for SuperMIC. But in practical it varies from case to case depending on users' codes.
Back to top16. How to achieve ppn=N?
Achieving ppn=N
When a job is submitted, the setting of processes per node must match certain fixed values depending on the queue on cluster: in workq or checkpt queue, ppn=8 on Philip, ppn=16 on SuperMike, ppn=20 on SuperMIC and QB2, and ppn=48 on QB3. A few clusters may have a single queue, which allows ppn=1. However, there is a way for a user to achieve ppn=N, where N is an integer value between 1 and the usual required setting on any cluster. This involves generating a new machine/host file to use with mpirun which has with N entries per node.
The machine/host file created for a job has its path stored in the shell variable PBS_NODEFILE. For each node requested, the node host name is repeated ppn times in the machine file. Asking for 16 nodes on QB2, for instance, results in 320 names appearing in the machine machine (i.e. 8 copies for each of 16 node names, since ppn=20). With a little script magic, one can pull out all the unique node names from this file and put them in a new file with only N entries for each node, then present this new file to mpirun. The following is a simple example script which does just that. But, it is important to keep in mind that you will be charged SUs based on ppn=20 since only entire nodes are allocated to jobs.
#!/bin/bash
#PBS -q checkpt
#PBS -A my_alloc_code
#PBS -l nodes=16:ppn=8
#PBS -l cput=2:00:00
#PBS -l walltime=2:00:00
#PBS -o /work/myname/mpi_openmp/run/output/myoutput2
#PBS -j oe
# Start the process of creating a new machinefile by making sure any
# temporary files from a previous run are not present.
rm -f tempfile tempfile2 newmachinefile
# Generating a file with only unique node entries from the one provided
# by PBS. Sort to make sure all the names are grouped together, then
# let uniq pull out one copy of each:
cat $PBS_NODEFILE | sort | uniq >> tempfile
# Now duplicate the content of tempfile N times - here just twice.
cat tempfile >> tempfile2
cat tempfile >> tempfile2
# Sort the content of tempfile2 and store in a new file.
# This lets MPI assign processes sequentially across the nodes.
cat tempfile2 | sort > newmachinefile
# Set the number of processes from the number of entries.
export NPROCS=`wc -l newmachinefile |gawk '//{print $1}'`
# Launch mpirun with the new machine/host file and process count.
# (some versions of mpirun use "-hostfile" instead of "-machinefile")
mpirun -np $NPROCS -machinefile newmachinefile your_program
Back to top
17. How to monitor PBS stdout and stderr?
Currently, PBS is configured so that the standard output/error of their jobs are redirected to temporary files and copied back to the final destination after their jobs finish. Hence, users can only access the standard output after their jobs finish.
However, PBS does provide another method for users to check standard output/error in real time, i.e.
qsub -k oe pbs_script
The -k oe option at the qsub command line specifies that standard output or standard error streams will be retained on the execution host. The stream will be placed in the home directory of the user under whose user id the job executed. The file name will be the default file name given by: where is the name specified for the job, and is the sequence number component of the job identifier. For example, if a user submits a job to Queenbee with job name "test" and job id "1223", then the standard output/error will be test.o1223/test.e1223 in the user's home directory. This allows users to check their stdout/stderr while their jobs are running.
Back to top18. How to decipher underutilization error emails?
Underutilized Message Decoder
The HPC@LSU systems run monitors which assess how well running jobs are utilizing nodes. They will send the job owners emails to report unusual utilization patterns, such as idle nodes in multi-node jobs, or using excessive amounts of memory. Each such message has a header section that describes the basic problem, and a statistics section that reports information collected by the job manager. This document expands the somewhat terse messages into simpler explanations.
The variable names used as closely related to PBS options, such as ppn (processors per node), job (job number), and wall_time. More detailed information is available:
- A dictionary of terms
- E124 - Exceeded Memory Allocation Message
- E130 - Unused Nodes Message
- E131 - Too Many Unused Nodes Message
- E132 - Low Memory Usage Message
- E133 - Low Load Message.
- E135 - Low CPU Percent Message.
19. How to establish a remote X11 session?
From *nix
Since ssh and X11 are already on most client machines running some sort of unix (Linux, FreeBSD, etc), one would simply use the following command:
% ssh -X -Y username@remote.host.tdl
Once successfully logged in, the following command should open a new terminal window on the local host:
% xterm&
An xterm window should appear. If this is not the case, email us.
From Mac OS X
An X11 service is not installed by default, but one is available for installation on the OS distribution disks as an add-on. An alternative would be to install the XQuartz version. Make sure the X11 application is running and connect to the cluster using:
% ssh -X -Y username@remote.host.tdl
From Windows
Microsoft Windows does not provide an X11 server, but there are both open source and commercial versions available. You also need to install an SSH client. Recommended applications are:
- MobaXterm - a Windows ssh client with X11 server integrated (recommended)
- Xming - a Windows X11 server
- PuTTY - a Windows ssh client
When a PuTTY session is created, make sure the "X11 Forwarding Enabled" option is set, and that the X11 server is running before starting the session.
Testing
Once Xming and puTTY have been set up and in stalled, the following will provide a simple test for success:
- start Xming
- start puTTY
- connect to the remote host (make sure puTTY knows about Xming for this host)
Once successfully logged in, the following command should open a new terminal window on the local host:
% xterm&
An xterm window should appear. If this is not the case, refer to "Trouble with Xming?" or email us.
Note About Cygwin
Cygwin is still a useful environment, but is too complicated and contains too many unnecessary parts when all one wants is to interface with remote X11 sessions.
Advanced Usage
The most important connection that is made is from the user's client machine to the first remote host. One may "nest" X11 forwarding by using the ssh -XY command to jump to other remote hosts.
For example:
1. on client PC (*nix or Windows), ssh to remotehost1
2. on remotehost1 (presumably a *nix machine), ssh -XY to remotehost2
3. on remotehost2 (presumably a *nix machine), ssh -XY to remotehost3
...
8. on remotehost8 (presumably a *nix machine), ssh -XY to remotehost9
9. on remotehost9, running an X11 application like xterm should propagate the remote window back to the initial client PC through all of the additional remote connects.
Back to top20. How to run interactive jobs?
Interactive Jobs
Interactive jobs give you dedicated access to a number of nodes, which is handy (and the preferred way) to debug parallel programs, or execute parallel jobs that require user interaction. On the Linux clusters, job submission is performed through PBS or SLURM.
For PBS, interactive jobs can be started by executing qsub without an input file:
[user@mike1]$ qsub -I -l nodes=2:ppn=4 -l walltime=00:10:00 -q workq
For SLURM, interactive jobs can be started by executing srun without an input file:
[user@qbc1]$ srun -t 1:00:00 -n8 -N1 -A your_allocation_name -p single --pty /bin/bash
As with any other job request, the time it takes to actually begin executing depends on how busy the system is and the resources requested. You have the option of using any available queue on the system, so matching the resources with the queue will tend to decrease the wait time.
Once the job starts running, you will be automatically logged into a node and can begin issuing commands. This PBS example starts up a 16-process MPI program named program05:
[user@mike1]$ qsub -I -l nodes=1:ppn=16 -l walltime=01:00:00 -q workq [user@mike026]$ cd /work/user [user@mike026]$ mpirun -hostfile $PBS_NODEFILE -np 16 ./program05
The set of nodes is yours to use for the length of time requested. If desired, one can also create an X-windows connection to display graphical information on your local machine. The syntax for PBS is:
[user@mike1]$ qsub -I -X -l nodes=1:ppn=16 -l walltime=01:00:00
The syntax for SLURM is:
[user@qbc1]$ srun --x11 -t 1:00:00 -n8 -N1 -A your_allocation_name -p single --pty /bin/bash
One thing to note is there are no queues designated specifically for interactive jobs. This may be common on some other clusters, but here users may initiate an interactive session in any queue they deem most appropriate. On any cluster, issuing the command:
$ qstat -q
will report the queues available, indicate if they are running, and show the max wallclock time set on each for the batch job. The max wallclock of the batch job may be changed as demand on a cluster varies, while in general, the max wallclock of the interactive job is 12 hours. so the information of max wallclock does not appear in the user guide. Queue choice is driven by many reasons. For example, a workflow may require starting a process interactively and then be left to run on its own. Users have a wider choice of nodes for doing testing of large applications, which allows interactive jobs to start running in a shorter amount of wait time than if they had to wait on a special queue.
Those running interactive jobs should also become familiar with another queue-related command:
$ qfree
This command gives a very brief summary for each queue, indicating how many nodes are in use and how many jobs are waiting in it. While most queues allocate all the cores in a node to a job, the single queue allows for a variable number of cores. On Philip, for instance, this would be 1 to 8 cores. In many cases this fact can be used to control memory available to a job. Basically, the fair use of the memory would be 1/8'th per core. If a job requires more memory, but only one core, then the user may request additional cores, but only run on 1. For instance, if half the memory is needed, the job should request 4 cores, but may then run on from 1 to 4 cores as needed.
There are a drawbacks to running interactively. First, the jobs leave very few log files behind so if you do have a problem there isn't much the system admins or user services can do to help you. Second, they start when resources become available -- if that is 4am and you aren't sitting in front of a computer, the node(s) will likely sit idle for a long time. Be aware that if an interactive job is idle for a long time, and there are other jobs waiting waiting in the queue, it may be killed by the system. Another potential problem is that should the head node have to be rebooted, all running interactive jobs are killed.
Back to top21. How to setup SSH keys?
Setting Up SSH Keys Among Nodes
- Login to cluster head node
- Make sure ~/.ssh exists:
$ mkdir -p ~/.ssh - Change to the .ssh directory:
$ cd ~/.ssh - Generate keys:
$ ssh-keygen -b 1024 -t dsa -f ~/.ssh/id_dsa.mynode_key - Authorize the Public Key:
$ cat ~/.ssh/id_dsa.mynode_key.pub >> ~/.ssh/authorized_keys
Test Set Up
From the head node, attempt to ssh into a compute node:
$ ssh -i ~/.ssh/id_rsa.node_key _compute_node_
If access is gained without being prompted for a password, then this has been set up properly.
Back to top22. How to compile MPI programs?
MPI (messeage passing interface) is a standard in parallel computing for data communication across distributed processes.
Building MPI applications on LONI 64 bit Intel cluster
The proper way to compile with the MPI library is to use the compiler scripts installed with the libary. Once your favor MPI (i.e. OpenMPI, MPICH, MVAPICH2, etc) and compiler suite (i.e. Intel, GNU) have been set up using Modules, you're good to go.
The compiler command you use will depend on the language you
program in. For instance, if you program in C, irregardless of whether
its the Intel C compiler or the GNU C compiler, the command would
be mpicc. The command is then used exactly as one
would use the native compiler. For instance:
$ mpicc test.c -O3 -o a.out $ mpif90 test.F -O3 -o a.out
There are slight differences in how each version of MPI launches a program for parallel execution. For that refer to the specific version information. But, by way of example, here is what a PBS job script might look like:
#!/bin/bash
#PBS -q workq
#PBS -A your_allocation
#PBS -l nodes=2:ppn=16
#PBS -l walltime=20:00:00
#PBS -o /scratch/$USER/s_type/output/myoutput2
#PBS -j oe
#PBS -N s_type
export HOME_DIR=/home/$USER/
export WORK_DIR=/work/$USER/test
export NPROCS=`wc -l $PBS_NODEFILE |gawk '//{print $1}'`
cd $WORK_DIR
cp $HOME_DIR/a.out .
mpirun -machinefile $PBS_NODEFILE -np $NPROCS $WORK_DIR/a.out
MPI example launched in SLURM job can be found here.
Back to top23. How to install VASP?
Installing VASP
LSU HPC currently holds a VASP maintenance license and provides a system-wide compiled installation of VASP on LSU and LONI HPC systems. To use VASP on LSU or LONI HPC resources, users must be authorized VASP users registered on the official VASP Portal. Before accessing VASP on LSU/LONI HPC systems, please email sys-help@loni.org with your email address associated with your VASP Portal account. We will verify that the provided email address is registered and authorized on the VASP Portal. Once verified, the user will be added to the VASP user group on LSU/LONI HPC systems and granted access to the system-installed VASP.
Back to top24. Are LONI or LSU HPC systems backed up?
No. A user must do this for himself.
For small sets of important files (not large data files!) git or subversion may be a good way to manage versioned copies. The git or Subversion client is available on all clusters.
Back to top25. Cluster email?
Electronic mail reception is not supported on the clusters. In general, email sent to user accounts on the clusters will not be received or delivered.
Email may be sent from the clusters to facilitate remote notification of changes in batch job status. Simply include your email in the appropriate script field.
Back to top26. What is my disk space quota on clusters?
Dell Linux clusters
Home Directory
For all LONI and LSU HPC clusters, the /home quota is 5 GB except for QB3, which has 10 GB of /home quota. Files can be stored on /home permanently, making it an ideal place for your source code and executables. In the meanwhile, it is not a good idea to use /home for batch job I/O.
Work (Sratch) Directory
Please note that the scratch space should only be used to store output files during job execution, and by no means for long term storage. Emergency purge without advanced notice may be executed when the usage of disk approaches its full capacity.
For all LONI and LSU HPC clusters, no disk space quota is enforced on /work (/scratch) but we do enforce a 60-90 days purging policy, which means that any files that have not been accessed for the last 60-90 days will be permanently deleted. Also, a quota for the total number of files is 4 million.
Checking One's Quota
Issuing the following command,
$ showquota
results in output similar to:
Hard disk quotas for user ychen64 (uid 11596):
Filesystem MB used quota files fquota
/homem 3780 5000 54133 0
/work 8344 0 221603 4000000
Notes on Number of Files in a Directory
All users should limit the number of files that they store in a single directory to < 1000. Large numbers of files stored within a single directory can severly degrade performance, negatively impacting the experience of all individuals using that filesystem.
Back to top27. File storage on LONI clusters
Home Directory
Files can be stored on /home permanently, which makes it an ideal place for your source code and executables. The /home file system is meant for interactive use such as editing and active code development. Do not use /home for batch job I/O.
Work (Scratch) Directory
The /work volume on all LONI clusters is meant for the input and output of executing batch jobs and not for long term storage. We expect files to be copied to other locations or deleted in a timely manner, usually within 30-120 days. For performance reasons on all volumes, our policy is to limit the number of files per directory to around 10,000 and total files to about 4,000,000.
No quota is enforced on /work but we do enforce a 60-90 days purging policy, which means that any files that have not been accessed for the last 60-90 days will be permanently deleted. An email message will be sent out weekly to users targeted for a purge informing them of their /work utilization.
Please do not try to circumvent the removal process by date changing methods. We expect most files over 60 days old to disappear. If you try to circumvent the purge process, this may lead to access restrictions to the /work volume or the cluster.
Please note that the /work volume is not unlimited. Please limit your usage rate to a reasonable amount. When the utilization of /work is over 80%, a 14 day purge may be performed on users using more than 2 TB or having more than 500,000 files. Should disk space become critically low, all files not accessed in 14 days will be purged or even more drastic measures if needed. Users using the largest portions of the /work volume will be contacted when problems arise and they will be expected to take action to help resolve issues.
Project Directory
There is also a project volume. To obtain a directory on this volume, an allocation request needs to be made. Allocations on this volume are for a limited time, usually 12 months. This volume uses quotas and is not automatically purged. An allocation of 100 GB can be obtained easily by any user, but greater allocations require justification and higher level of approval. Any allocation over 1 TB requires approval from the LONI allocations committee which meats every 3 months. Since this is a limited resource, approval is also based on availability.
Checking One's Quota
Issuing the following command,
$ showquota
results in output similar to:
Hard disk quotas for user ychen64 (uid 11596):
Filesystem MB used quota files fquota
/home 3105 5000 44537 0
/work 133 0 33849 4000000
/project 259782 300000 1676424 4000000
Back to top
28. Disk/Storage problems?
Often times, full disk partitions are the cause of many weird problems. Sometimes the error messages do not indicate an unwritable or unreadable disk, but the possibility should be investigated anyway.
Checking the Filesystems
Using the df command, a user may get a global view of the file system. df provides information such as the raw device name, mount point, available disk space, current usage, etc. For example,
% df Filesystem 512-blocks Free %Used Iused %Iused Mounted on /dev/hd4 524288 456928 13% 3019 6% / /dev/hd2 6291456 936136 86% 38532 26% /usr /dev/hd9var 2097152 1288280 39% 892 1% /var /dev/hd3 524288 447144 15% 1431 3% /tmp /proc - - - - - /proc /dev/hd10opt 1048576 297136 72% 11532 26% /opt /dev/sni_lv 524288 507232 4% 40 1% /var/adm/sni /dev/sysloglv 524288 505912 4% 635 2% /syslog /dev/scratchlv 286261248 131630880 55% 112583 1% /mnt/scratch /dev/globuslv 4194304 1337904 69% 23395 14% /usr/local/globus l1f1c01:/export/home 52428800 34440080 35% 109684 2% /mnt/home
The du program will calculate the amount of disk space being used in the specified directory. This is useful if a user needs to find some offending directory or file. It is often the case that a user exceeds his quota because of a small number of large files or directories.
Potential Issues
The Partition in Question is Full
Ensure that the directory that you are trying to write in is not full.
/tmp is Full
A lot of programs use this partition to dump files, but very few clean up after themselves. Ensure that this directory is not full because often times a user has no idea that the application they are using touchs /tmp. A user should contact sys-help@loni.org if this is found to be the case and they are not responsible for the data themselves.
/var is Full
A lot of system programs use this partition to store data, but very few use the space efficiently or clean up after themselves. Ensure that this directory is not full. A user should contact sys-help@loni.org if this is found to be the case.
Back to top29. Which text editors are installed on the clusters?
The following text editors are available:
- vi (See Google for the vi cheat sheet)
- vim
- emacs
- nano
30. PBS job chains and dependencies
PBS Job Chains
Quite often, a single simulation requires multiple long runs which must be processed in sequence. One method for creating a sequence of batch jobs is to execute the qsub to submit its successor. We strongly discourage recursive, or "self-submitting," scripts since for some jobs, chaining isn't an option. When your job hits the time limit, the batch system kills them and the command to submit a subsequent job is not processed.
PBS allows users to move the logic for chaining from the script and into the scheduler. This is done with a command line option:
$ qsub -W depend=afterok:<jobid> <job_script>
This tells the job scheduler that the script being submitted should not start until jobid completes successfully. The following conditions are supported:
- afterok:<jobid>
- Job is scheduled if the job <jobid> exits without errors or is successfully completed.
- afternotok:<jobid>
- Job is scheduled if job <jobid> exited with errors.
- afterany:<jobid>
- Job is scheduled if the job <jobid> exits with or without errors.
One method to simplify this process is to write multiple batch scripts, job1.pbs, job2.pbs, job3.pbs etc and submit them using the following script:
#!/bin/bash FIRST=$(qsub job1.pbs) echo $FIRST SECOND=$(qsub -W depend=afterany:$FIRST job2.pbs) echo $SECOND THIRD=$(qsub -W depend=afterany:$SECOND job3.pbs) echo $THIRD
Modify the script according to number of job chained jobs required. The Job <$FIRST> will be placed in queue while the jobs <$SECOND> and <$THIRD> will be placed in queue with the "Not Queued" (NQ) flag in Batch Hold. When <$FIRST> is completed, the NQ flag will be replaced with the "Queued" (Q) flag and will be moved to the active queue.
A few words of caution: If you list the dependency as "afterok"/"afternotok" and your job exits with/without errors then your subsequent jobs will be killed due to "dependency not met".
Back to top31. Random number seeds
The random number functions in most language libraries are actually pseudo-random number generators. Given the same seed, or starting value, they will reproduce the same sequence of numbers. If a relatively unique sequence is required on multiple nodes, the seeds should be generated from a source of high entropy random bits. On Linux systems, this can be accomplished by reading random bits from the system file /dev/random.
C/C++
The read can readily be done with fread() in C/C++ by treating /dev/random as a stream.
int main ( void )
{
#include <stdio.h>
double x;
int i[2];
FILE *fp;
fp = fopen("/dev/random","r");
fread ( &x, 1, 8, fp );
fread ( i, 1, 8, fp );
fclose ( fp );
printf ( "%i %i %g\n", i[0], i[1], x );
return 0;
}
Fortran
In Fortran, the size of the variable determines how many bits will be read. The /dev/random file must be treated as a binary, direct access file, with a record length corresponding to the byte size of the variable being read into.
program main
real*8 x
integer*4 i(2)
open ( unit=1, file='/dev/random', action='read',
$ form='unformatted', access='direct', recl=8, status='old' )
read ( 1, rec=1 ) x
read ( 1, rec=1 ) i
close ( 1 )
print *, i, x
stop
end
Back to top
32. Known issues?
system(), fork() and popen()
Calls to system library functions system(), fork() and popen() are not supported by the Infiniband driver under the current Linux kernel. Any code that makes these calls inside the MPI scope (between MPI initialization and finalization) will likely fail.
Back to top33. DOS/Linux/MAC text file problems?
Convert DOS Text Files to UNIX Text Files
Text File Formats
Text files contain human readable information, such as script files and programming language source files. However, not all text files are created equal - there are operating system dependencies to be aware of. Linux/Unix text files end a line with an ASCII line-feed control character which has a decimal value of 10 (Ctrl-J). Microsoft Windows (or MS-DOS) text files use two control characters: an ASCII carriage return (decimal 13 or Ctrl-M), followed by a line-feed. Just to mix things up, Apple OS/X text files use just a carriage return.
Problems can, and do, arise if there is a mismatch between a file's format and what the operating system expects. Compilers may be happy with source files in mixed formats, but other apps, like PBS, throw strange errors or just plain give up. So, it is important to make sure text file formats match what the operating system expects, especially if you move files back and forth between systems.
How To Tell
On most systems, the file command should be sufficient:
$ file <filename>
Assuming a file named foo is a DOS file on Linux, you may see something like this:
$ file foo foo: ASCII text, with CRLF line terminators
This indicates foo is a DOS text file, since it uses CRLF (carriage-return/line-feed). Some editors, such as vim and Emacs, will report the file type in their status lines. Other text based tools, such as od can also be used to examine the ASCII character values present, exposing the end-of-line control characters by their value.
How To Convert
If you're lucky, the system may have utilities installed to convert file formats. Some common names include: dos2unix, unix2dos, cvt, and flip. If they are not present, then you can draw on one of the basic system utilities to do the job for you.
The simplest involves using an editor, such as vim or Emacs. For instance, to use vim to control the format of the files it writes out, try setting the file format option using the commands :set ff=unix or :set ff=dos. Regardless of what format the file was read in as, it will take the format last set when written back out.
Another option would be to use a command line tool, such as tr (translate), awk, set, or even a Perl or Python script. Here's a tr command that will remove carriage returns, and any Ctrl-Z end-of-file markers from a DOS file (note that the character values are octal, not decimal):
$ tr -d '\15\32' < dosfile.txt > linuxfile.txt
How To Avoid the Problem
There aren't many ways to reliably avoid this problem if you find yourself moving back and forth between operating systems.
- Use vim on all your systems, and modify the startup config file to always set ff=unix, regardless of the OS you are on.
- Use Windows tools that produce proper Linux files (vim or notepad++, for instance).
- Install a conversion tool on your system, and apply it before moving the file. Most tools are smart enough to converting a file only if required (e.g. if converting to DOS and a file is already in DOS format, leave it alone). flip is available in source form, and works on DOS, MAC OS/X, and Linux.
- Move text files in a Zip archive, using the appropriate command line option to translate end-of-line characters. However, you'll have trouble if you accidently translate a binary file!
- Just say NO to cross-platform development!
34. How to use Singularity container on the clusters?
Information about running applications through singularity container image can be found here:
- Introduction to Singularity
- Availibility
- Basic singularity syntax
- Running singularity images under default cluster system directories
- Running user's own singularity images
Introduction to Singularity
Singularity is an open-source container platform. It allows users to pack an application and all of its dependencies into a single image (file). Developed at Lawrence Livermore National Laboratory, it has become the most popular container platform among HPC user communities.
Availibility
Singularity is available on all compute nodes of LSU and LONI HPC clusters, thus user can run applications via the singularity container through either interactive or batch jobs. Singularity is not installed on the headnode, nor available as a software module key.
Running applications through singularity container
Basic singularity syntax
The general usage form of singularity is:
singularity <command> <options> <arguments>
To shell into the singularity image on HPC or LONI clusters, use the below command syntax:
singularity shell -B /work /path/to/the/singularity/image
To run an application through a singularity image, use the below command syntax:
singularity exec -B /work /path/to/the/singularity/image name_of_exe <exe_arguments>
Explanation of arguments after the command singularity:
- shell: Run a shell within the container image
- exec: Run a command within the container image
- -B (--bind strings): a user-bind path specification, on HPC/LONI clusters, it is necessary to bind the /work directory so singularity is able to access the /work directory on the cluster
Running singularity images under default cluster system directories
Currently on HPC and LONI clusters, images located under /project/containers/images/ are provided by HPC staff and typically include solutions for commonly requested software that are difficult to install on the cluster’s host operating system. Users can run their own singularity images (there is no longer the need to be added to the "singularity" user group), and we strongly encourage users to build and run their own images.
Below example shows the command to run an application named "maker" through the singularity image available under path /project/containers/images/maker-2.31.11-ubuntu-14.04.mpich2-1.5.simg, this image is built by HPC user services staff:
[fchen14@shelob019 example_01_basic]$ singularity exec -B /work /project/containers/images/maker-2.31.11-ubuntu-14.04.mpich2-1.5.simg maker -h
MAKER version 2.31.11
Usage:
maker [options] <maker_opts> <maker_bopts> <maker_exe>
...
For applications that need to use Nvidia's GPU on the compute node:
- Make sure you are running the application on a GPU node.
- pass the --nv option to the singularity command that run (singularity shell), or otherwise execute containers (singularity exec), which will setup the container’s environment to use an NVIDIA GPU and the basic CUDA libraries to run a CUDA enabled application. Detailed explanation of the --nv flag can refer to this link.
Below example shows the command to run a python script "gcn.py" using the pytorch image:
[fchen14@smic385 examples]$ singularity exec --nv -B /work,/usr/lib64 /project/containers/images/singularity/pytorch-1.5.1-dockerhub-v4.simg python gcn.py Epoch: 001, Train: 0.2000, Val: 0.0740, Test: 0.0740 ... Epoch: 199, Train: 1.0000, Val: 0.8020, Test: 0.8240 Epoch: 200, Train: 1.0000, Val: 0.8020, Test: 0.8240
Running user's own singularity images
Users are encouged to build their own singularity image on their own desktop/laptop that they have the "root" permission, upload to /home, /work (note that files in /work are subject to purge) or /project directory and then run them. There are many resources and tutorials on how to build singularity images, you can refer to singularity official website for more details.
Once your singularity image is successfully built, upload your own image to the cluster using either scp or rsync:
localhost $ scp /path/to/local/singularity/image username@remote.host:/home/or/work/dirBack to top
Users may direct questions to sys-help@loni.org.